The primary method for adding new data streams to Azure Data Explorer (ADX) is through using Event Hubs / Kafka topics. We can directly write to ADX tables if needed but using Event Hubs provides a scalable resiliency for message ingestion that ensure that messages aren't lost if for any reason our ADX cluster was offline or unable to process messaging.
The diagram below represents the components used in receiving raw data from an Event Hub and transforming that data into a structured form that can be used by our Technology teams.
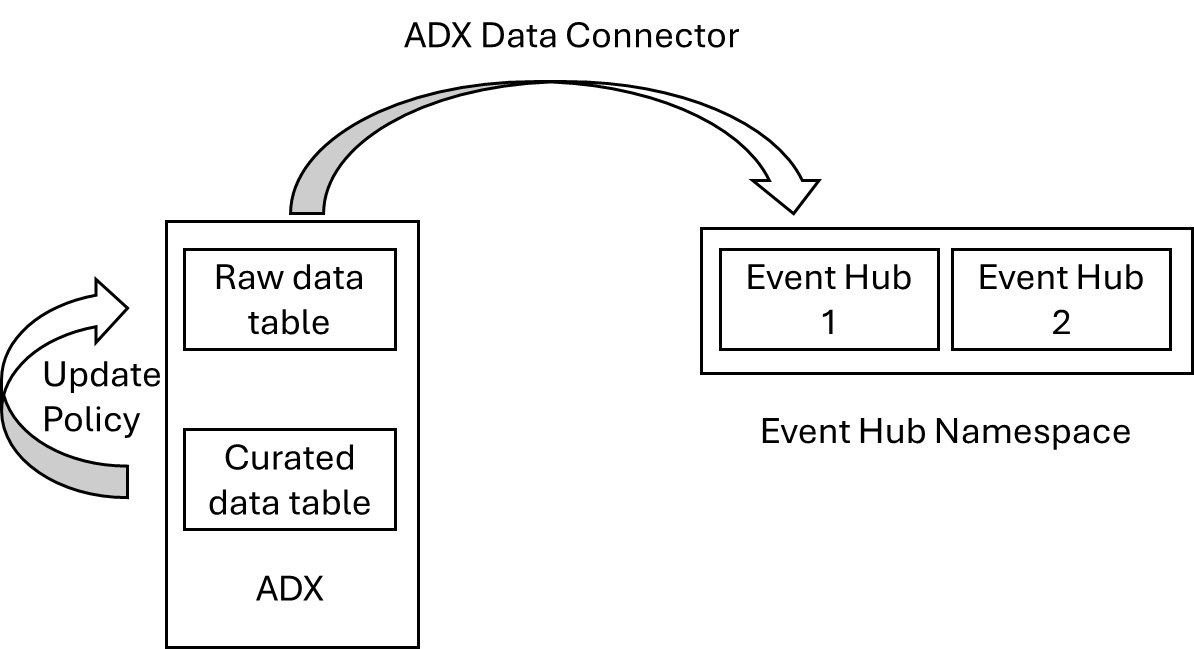
- Raw data is streamed into an Event Hub from an end system. Most Microsoft systems support direct streaming to Event Hubs and it's common for many Enterprise systems to support Kafka log streaming as well. Sometimes we will have to write Function Apps to submit event logs to Event Hubs for systems that only support REST based log retrieval.
- We need to create a "raw" data table within ADX to receive the data from the Event Hub. Typically this is in a single field of a "dynamic" data type that can hold the entire JSON representation of the incoming event.
- We will create an ADX data connection from our database which tells the system where to get its raw data from and how to store the records.
- We will create the schema for the target table. For this we will use published Microsoft's Azure Monitor schemas. It's much better to derive the schemas from Log Analytics than rely on the published schemas as there are mistake in the published documentation. An example of how to derive a schema can be found here: https://www.laurierhodes.info/node/154
- We will create a KQL function that expands an event record from the single dynamic field in the raw table to aligning with the expected full schema. This function will then be enabled as an "Update Policy" to run against every new record that enters the raw data table.
As an example, I am going to use a single Microsoft Defender event stream to show the end-to-end process in getting ASX data ingested correctly.
Start with an Event Hub
The first step will be to create an Event Hub to receive streaming events from Defender. I've already created an Event Hubs Namespace in my Azure subscription. Defender will create Event Hubs automatically (or if you use the same Event Hub names you can pre-create the hubs through code. To enable Defender event streaming, log in to https://security.microsoft.com/ and navigate to Settings -> Microsoft Defender XDR -> Streaming API
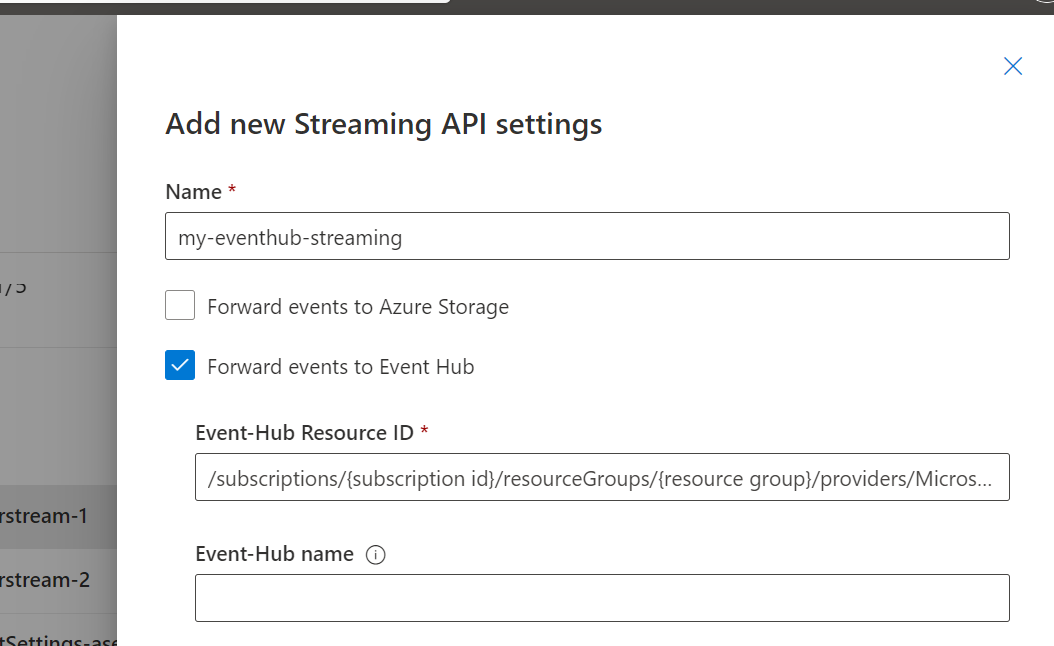
If you leave the Event-Hub name field blank, event hubs will be automatically created using standardised names.
Tip: You can always find Resource Ids of Azure services by looking at the JSON View of an object.
Before I do any work in ADX, I want to have a look at what the event records look like as they come into the Event Hub. I'll drill down into the Event Hub Namespace -> Entities and find the Event Hub I want to look at.
Within the Event Hub, we can use the the Process Data Feature.
This will expose the capability of having real-time insights with streaming data.
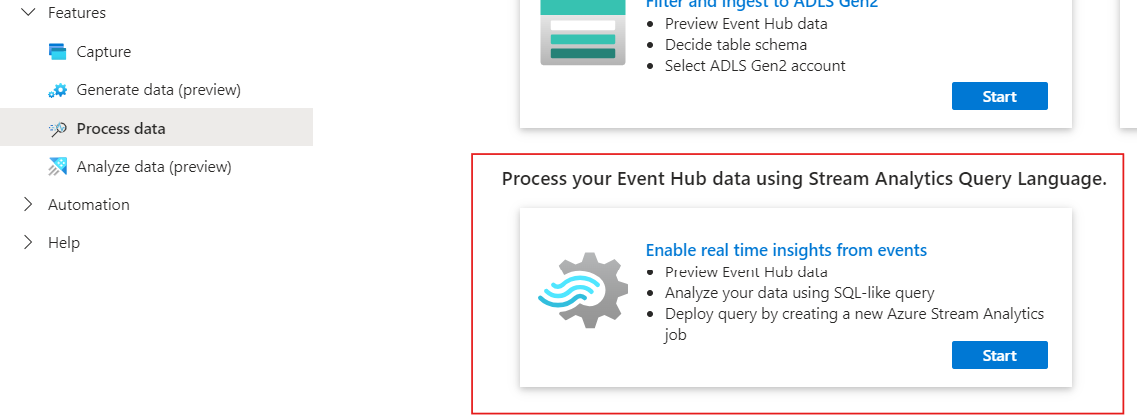
Once enabled, I can view Raw messages in JSON, the same way that they will eventually arrive in ADX.
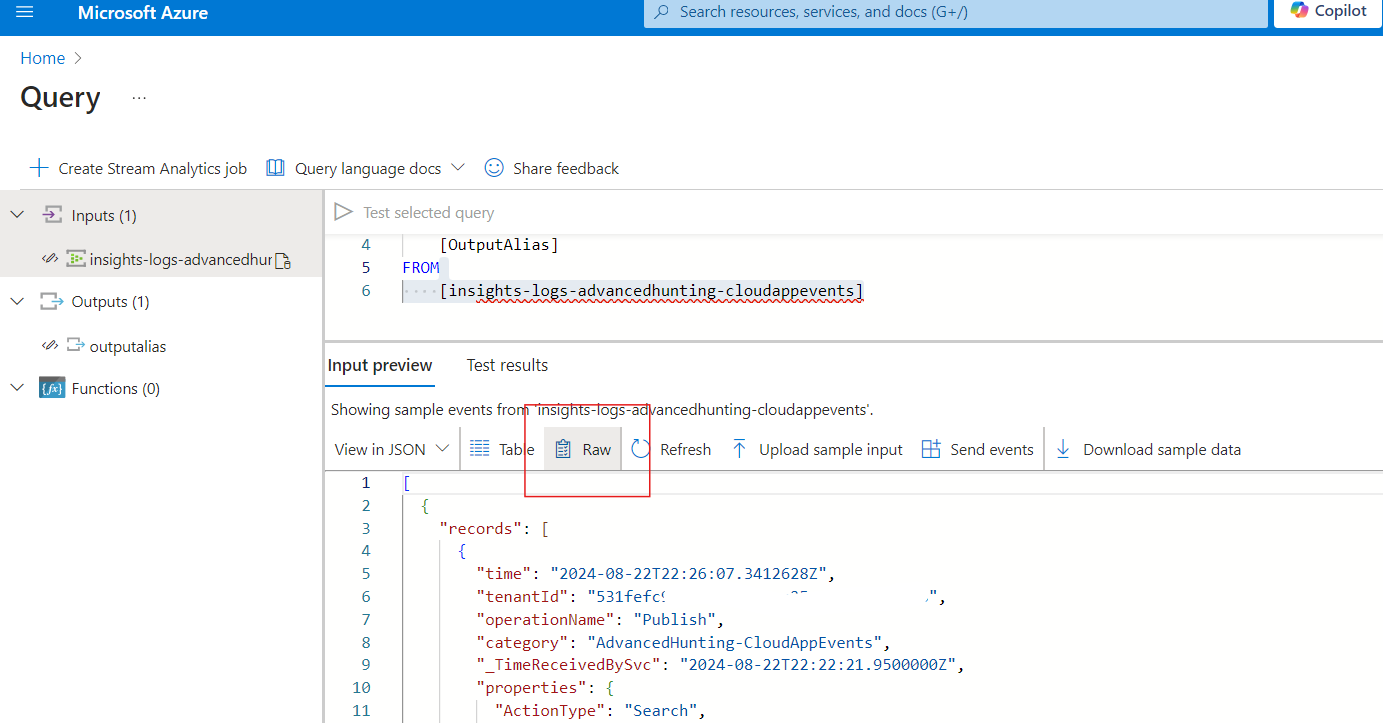
I'm going to copy one of these records to notepad for reference later.
While I'm here, as this is a newly provisioned Event Hub namespace, I'm going to use the Access Control blade (IAM) and ensure that my ADX cluster has been assigned the Azure Event Hub Data Receiver role so it may receive data from all event gubs on the namespace.
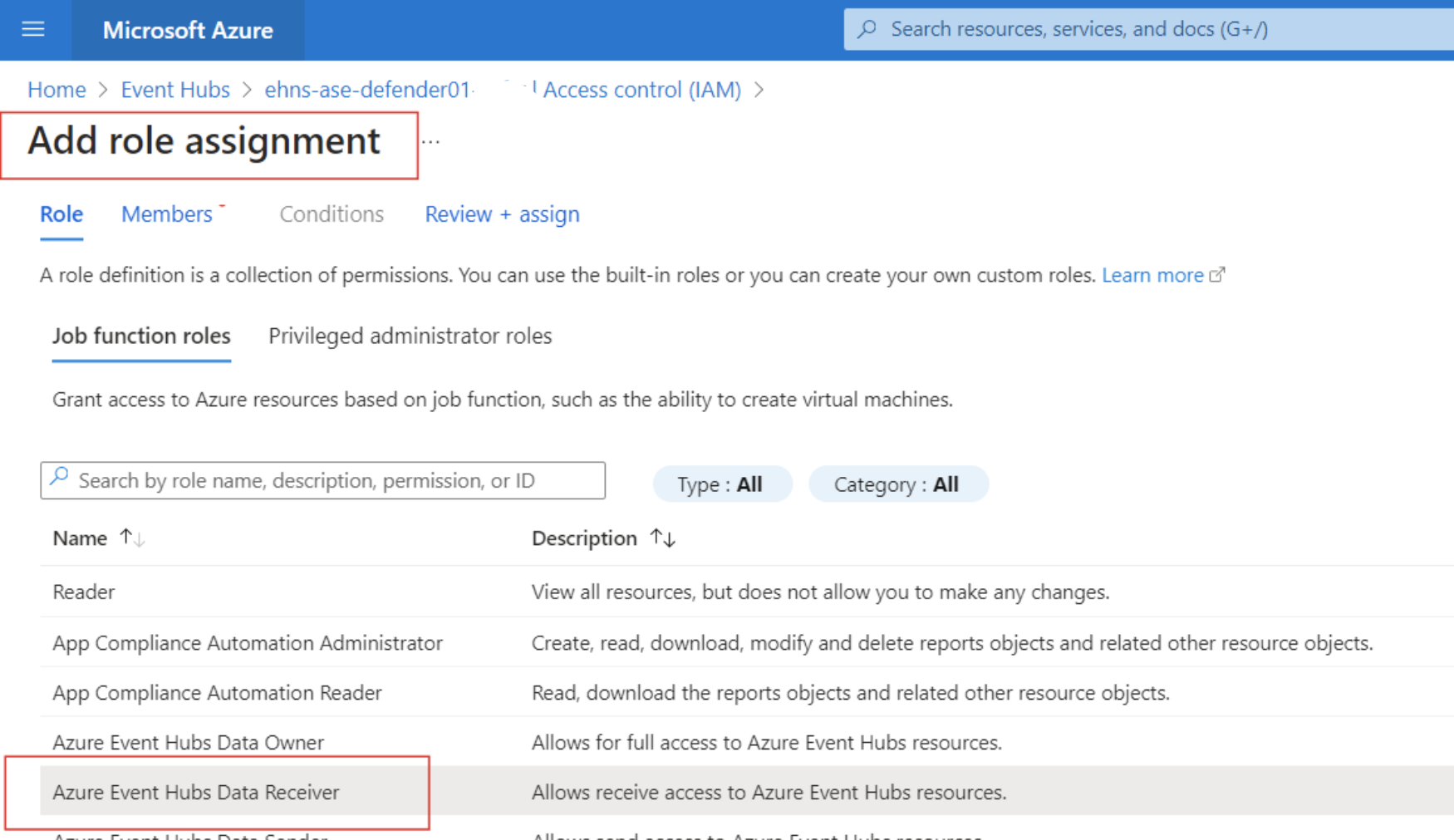
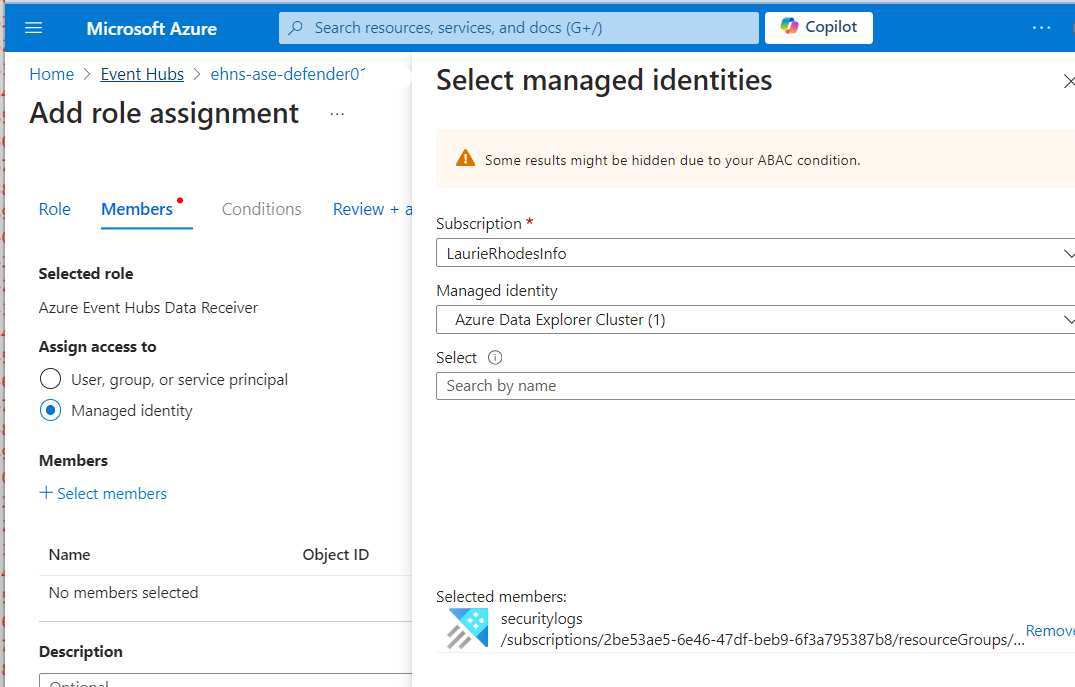
I have enough information to start working with ADX.
Creating ADX tables
Everything in ADX is done using KQL which I will do using the Query blade of my newly created ADX database. I can do this with a CO/CD pipeline too but for the purpose of demonstration, testing my KQL is bet done here.
Create the Raw data table
.create-merge table CloudAppEventsRaw (records:dynamic)First I'll create the table for raw data, which will have one field called "records" that is dynamic. This is going to be the same with every new table I create.
When I saw the records coming into the Event Hub I noticed that all records come into the system in an array of "records". Take note of case sensitivity with this,
I need to create an ingestion mapping that will be used by ADX to map the data stream to my new "raw" table.
.create-or-alter table CloudAppEventsRaw ingestion json mapping 'CloudAppEventsRawMapping' '[{"column":"records","Properties":{"path":"$.records"}}]'
The mapping tells ADX that data coming in from the ".records" path nees to be mapped to my newly created records column.
Data Connector
I'll create a data connector that can use the mapping I've created to get raw data from the Event Hub. Data Connectors are referenced of the left hand side of the database.
I'll add a new data connector.
Most of the fields with the data connector can be populated by drilling down to my Event Hub and the "raw" yable I have created.
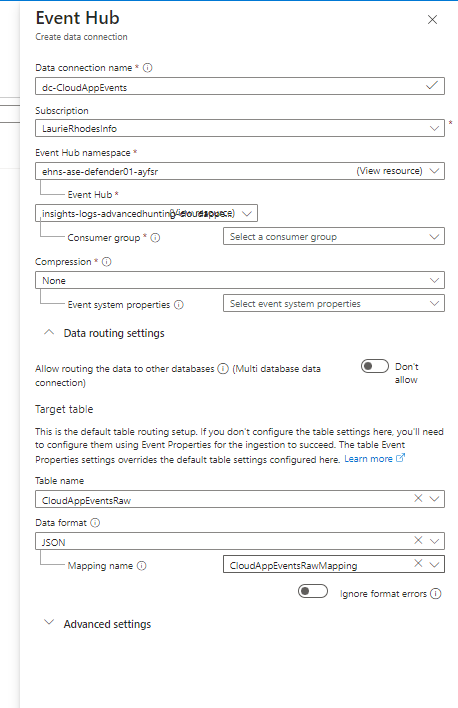
The data will always come in JSON format and I selected the mapping created in the previous step.
Once the data connector is enabled, I'll be able to go back and verify that I do have data coming in.
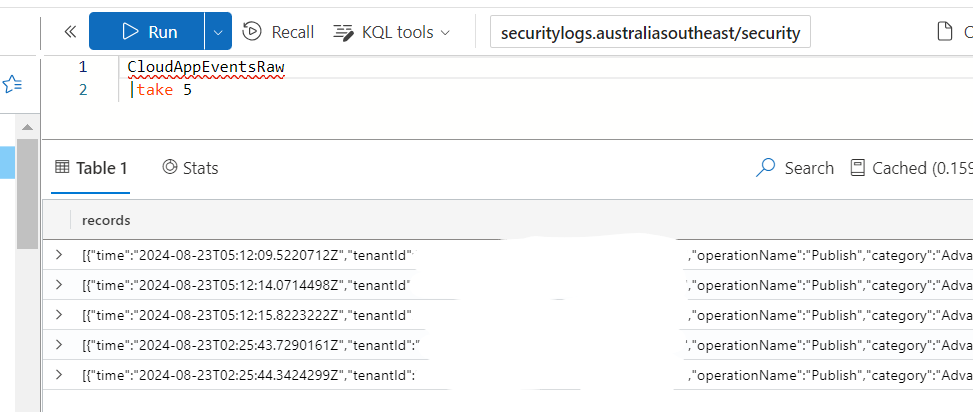
Target table creation
I know that I want data transformed into the Microsoft schema for CloudAppEvents so I will derive the schena from Log Analytics as shown here: https://www.laurierhodes.info/node/154
.create-merge table CloudAppEvents(
TenantId:string,
AccountId:string,
AccountType:string,
AdditionalFields:dynamic,
RawEventData:dynamic,
ReportId:string,
ObjectId:string,
ObjectType:string,
ObjectName:string,
ActivityObjects:dynamic,
ActivityType:string,
UserAgent:string,
ISP:string,
City:string,
CountryCode:string,
IsAnonymousProxy:bool,
IsExternalUser:bool,
IsImpersonated:bool,
IPAddress:string,
IPCategory:string,
IPTags:dynamic,
OSPlatform:string,
DeviceType:string,
IsAdminOperation:bool,
AccountDisplayName:string,
AccountObjectId:string,
AppInstanceId:int,
ApplicationId:int,
Application:string,
ActionType:string,
UserAgentTags:dynamic,
TimeGenerated:datetime,
Timestamp:datetime,
SourceSystem:string,
Type:string)
This will create the table in ADX. So far so good!
Expand Function
The tricky part can be the detective work of mapping data in the raw JSON to the correct fields of the Azure Monitor schema. A bit of trial and effort is involved with this. My function is going to take data from the raw table and project the various bits of data to the right field names and casting them to the expected data types as I go.
We need to think about the type of data that is in the raw table before we proceed.
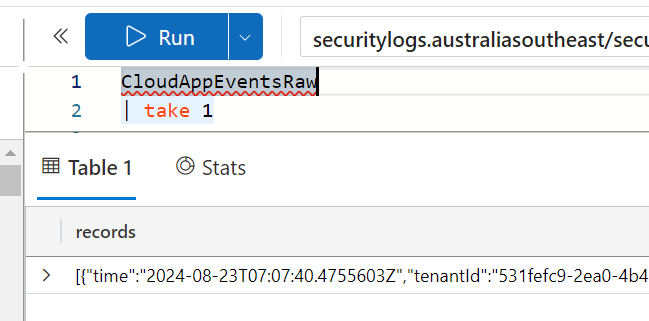
The records coming into the raw table are all encased in square brackets - which declares them to be an array. Kusto doesn't automatically expand arrays; it treats the entire array as a single entity. This wont give me the ability to select different fields from the raw data unless the array is flattened.
In KQL the mv-expand operator flattens the array, creating a separate row for each object in the array. This allows the project statement to access individual properties inside each JSON object.
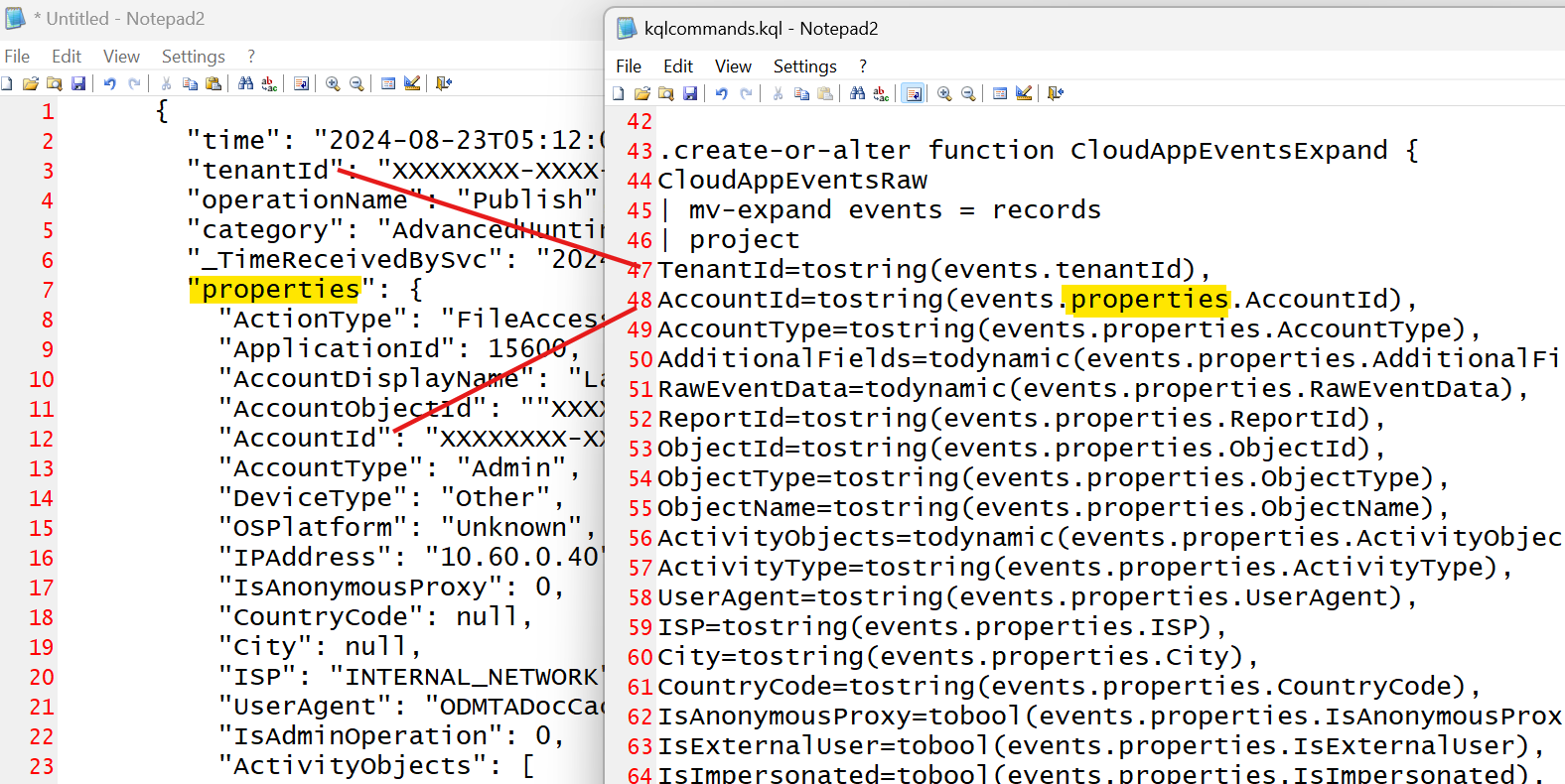
My function is going to start by flatening the array and referring to the flattened data column as "events" which seems to be in keeping with what others are doing on the Internet.
- The order I do this in must match the order of the columns I created in the table!
- The nesting in JSON is represented as a dot in KQL and this is all case sensitive.
- Notice how all data comes from the records table I created in the raw table and I use periods for matching the hierachy in my function.
.create-or-alter function CloudAppEventsExpand {
CloudAppEventsRaw
| mv-expand events = records
| project
TenantId=tostring(events.tenantId),
AccountId=tostring(events.properties.AccountId),
AccountType=tostring(events.properties.AccountType),
AdditionalFields=todynamic(events.properties.AdditionalFields),
RawEventData=todynamic(events.properties.RawEventData),
ReportId=tostring(events.properties.ReportId),
ObjectId=tostring(events.properties.ObjectId),
ObjectType=tostring(events.properties.ObjectType),
ObjectName=tostring(events.properties.ObjectName),
ActivityObjects=todynamic(events.properties.ActivityObjects),
ActivityType=tostring(events.properties.ActivityType),
UserAgent=tostring(events.properties.UserAgent),
ISP=tostring(events.properties.ISP),
City=tostring(events.properties.City),
CountryCode=tostring(events.properties.CountryCode),
IsAnonymousProxy=tobool(events.properties.IsAnonymousProxy),
IsExternalUser=tobool(events.properties.IsExternalUser),
IsImpersonated=tobool(events.properties.IsImpersonated),
IPAddress=tostring(events.properties.IPAddress),
IPCategory=tostring(events.properties.IPCategory),
IPTags=todynamic(events.properties.IPTags),
OSPlatform=tostring(events.properties.OSPlatform),
DeviceType=tostring(events.properties.DeviceType),
IsAdminOperation=tobool(events.properties.IsAdminOperation),
AccountDisplayName=tostring(events.properties.AccountDisplayName),
AccountObjectId=tostring(events.properties.AccountObjectId),
AppInstanceId=toint(events.properties.AppInstanceId),
ApplicationId=toint(events.properties.ApplicationId),
Application=tostring(events.properties.Application),
ActionType=tostring(events.properties.ActionType),
UserAgentTags=todynamic(events.properties.UserAgentTags),
TimeGenerated=todatetime(now()),
Timestamp=todatetime(events.properties.Timestamp),
SourceSystem='',
Type=''}I can test that function now and validate that my data is being properly transformed,

There is an element within the data that I'm handling differently and it deserves a dedicated blog post. This is the field TimeGenerated. This is a problematic field for SOC teams as it registers when data is processed by Log Analytics, not when the event actually occurs. I'm going to do the same thing with ADX and use TimeGenerated=todatetime(now()) to record when the data is processed. This will help me run automation against new data within ADX. Defender data is great because it uses a Timestamp field to record when an event occurred so I wont lose important data.
Update Policy
I have raw data flowing into my ADX "raw" table. I have a function that is doing ETL properly. The last thing I need to do is enable an Update Policy on my target table so each raw event automatically gets transformed by the function. I'll do this with KQL too.
.alter table CloudAppEvents policy update @'[{"Source": "CloudAppEventsRaw", "Query": "CloudAppEventsExpand()", "IsEnabled": "False", "IsTransactional": true}]'
.alter table CloudAppEvents policy update @'[{"Source": "CloudAppEventsRaw", "Query": "CloudAppEventsExpand()", "IsEnabled": "True", "IsTransactional": true}]'
The Policy instructs ADX that when an event record hits the CloudAppEventsRaw table, run the function I created to update the target table.
The reason I have the two commands, the first one that creates a policy that is disabled, is so I can paste the code in my CI/CD pipeline. I discovered that if a Policy is active when you alter the function, the previous version is cached. By adding a command to disable and re-enable the policy as part of my CI/CD script gets around this problem.
- Log in to post comments