With Azure Data Explorer we have to manually define the schema for each table created within the service.

The standard method for organising enterprise scale data ingest is by using Event Hubs (Kafka) as a means to regulate traffic volume and to provide a queued cache for ensuring data isn't lost if issues impact the ADX cluster.
Defender XDR, Entra and Sentinel are significant data sources that a Security Operations team is likley to want to ingest and retain data from. With Entra and Defender XDR this occurs through establishing Diagnostic Settings on the SaaS service and forwarding data to Event Hubs. With Sentinel we need to enable table level archive for event data forwarding. Each of these three feeds sends json data slightly differently and needs to have the data connection and data transformation modified to achieve a like-for-like table in ADX that might be seen in Sentinel or the online SaaS portals.
The first element with a running ADX database will be to create the destination tables for the data being streamed. There are a couple of ways to do this.
- Duplicate Log Analytics tables by script. There are two widely used scripts for this online but they don't fully account for the different field types that may exist within Log Analytics, tending to default to create fields as strings when they aren't. It probably doesn't matter too much but it still requires tables to exist in Log Analytics in the first place.
- Manual creation of tables based on the online published schemas eg. https://learn.microsoft.com/en-us/azure/azure-monitor/reference/tables/aacaudit. This is a good exercise to go through and useful if you don't have a table in Log Analytics to reference. There are examples where the online documentation isn't right which suggests the documentation hasn't had a robust quality assurance.
- Create the schema using KQL directly from the various source systems.
The KQL script works with Log Analytics, Defender and Entra consoles in outputting the KQL for creating the same table in ADX
let aztable = "EmailUrlInfo";
table(aztable)
| getschema
| extend Command=strcat(ColumnName, ': ', ColumnType)
| summarize mylist = make_list(Command)
| extend strCommand = tostring(mylist)
| extend strCommand = replace_string(strCommand, '"', '')
| extend strCommand = replace_string(strCommand, '[', '')
| extend strCommand = replace_string(strCommand, ']', '')
// Split the operation into parts to inject the aztable variable value
| extend strCommand = strcat(".create-merge table ", aztable, " (", strCommand, ')')
| project strCommandRunning the query will create a command that can be copies and used in the query window of an ADX database.
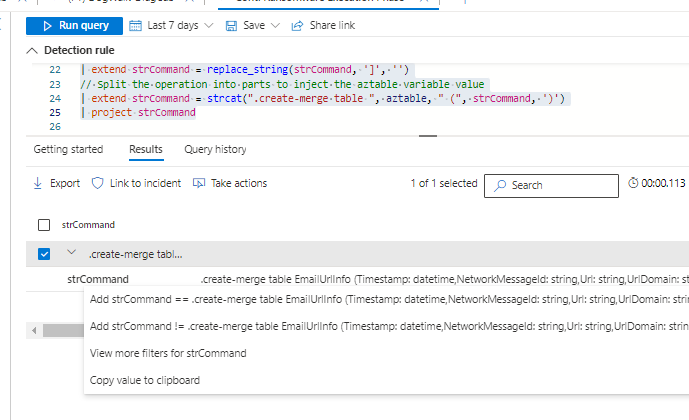
The output can be copied and run directly as a query against the target ADX database, or saved in a .kql file and used when deploying ADX through code.
Data Considerations
EmailUrlInfo is a simple, small table that highlights some of the issues as to why each table needs to be thought about as the schema is created in ADX.
Consider the schema from Defender XDR:
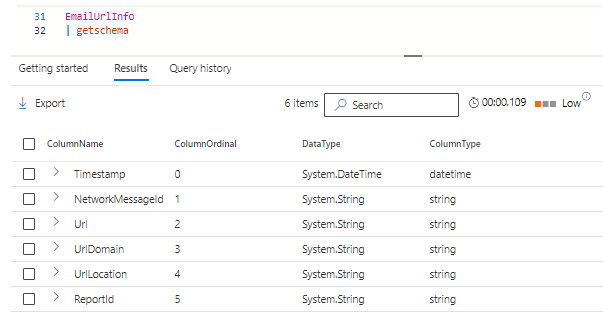
This particular table has 6 data fields in Defender XDR. When I look at the same table schema in Microsoft Sentinel it has 10 fields.
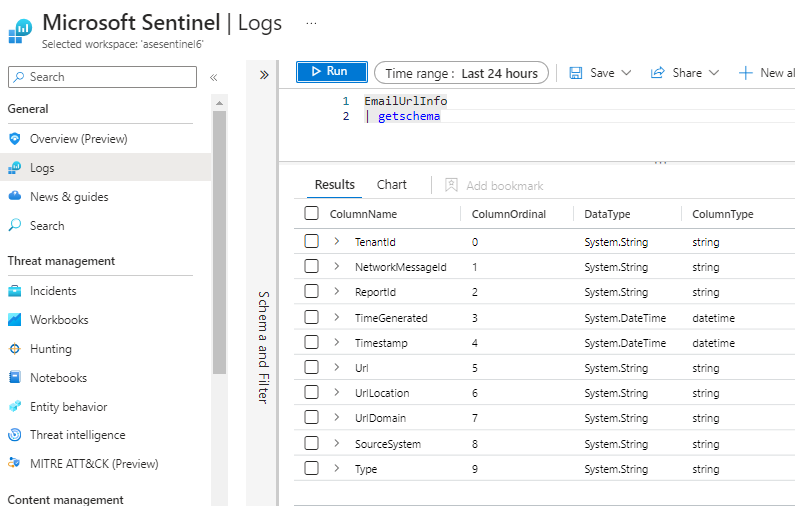
Microsoft's Azure Monitor schema documantion states the table has 11 fields.
https://learn.microsoft.com/en-us/azure/azure-monitor/reference/tables/emailurlinfo
I've highlighted the field additions that exist in Sentinel that aren't present in XDR,
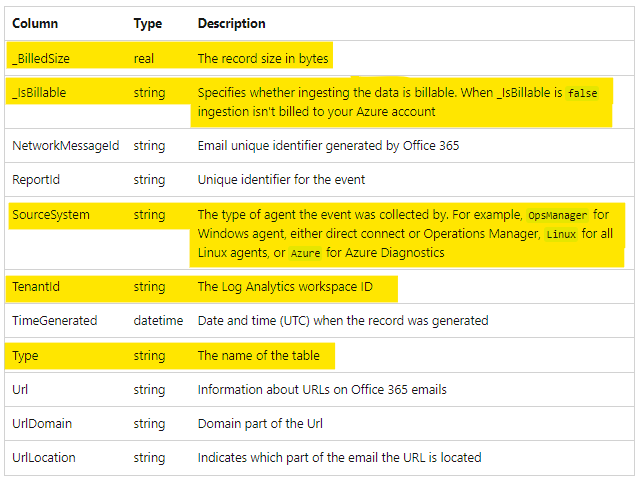
We can't say for certain exactly what the schema for this table should be as we have three conflicting or different representations of the same table and data.
Sentinel is designed to be used as a multi-tenant monitoring solution and due to its billing being calculated differently on certain tables, that explains the addition of the extra fields.
Two of the bigget issues are:
- When working with tables in ADX, the order of fields is important. This is really important for a professional SOC as well as we want the most important data returned in the first columns of a query. Defender XDR is aware of this and ordered data accordingly but Sentinel's column order doesnt do this. If I order columns the way Defender XDR does, I'll probably need to add additional columns that Sentinel uses to support multi-tenant capability.
- 'TimeStamp' and 'TimeGenerated' are inconsistently handled fields with Microsoft's security systems. TimeGenerated is when an event message arrives at a Microsoft system, not the actual time stamp on the event. There are some nasty aspects of this. Microsoft's CommonSecurityLog drops the time stamp of the event message completely, replacing it with 'TimeGenerated'. At the same time, the industry has got used to writing queries against TimeGenerated. Notice how the KQL schema documentation for this table doesn't show Timestamp existing as a field at all but it does actually exist in the Sentinel schema. Most tables simply have 'TimeGenerated' and in the situations where a time stamp is actually available, it's a dillema over re-mapping that data to actually be the TimeGenerated field, or alternately be completely nonstandard and ensure every table has a TimeStamp and use TimeGenerated to record the moment the event hits ADX.
I don't think there is a "right" answer with this but Microsoft's practice of discarding the time stamp on Common Event Format messages received over syslog & using 'TimeGenerated' is definately wrong.
This highlights the importance of deliberating on each table as it's onboarded into ADX rather than having blind faith in a script. Using ADX as a production security tool really forces us to think about data engineering seriously from the outset as whatever choices we make will become hard-set for the life of the ADX system.
- Log in to post comments