With Azure Data Explorer acting as my large data repository for security data, I need to plan for Disaster Recovery and long term archive of event data. This is achieved by establishing a Continuous Export of ingested data to a nominated Storage Account.
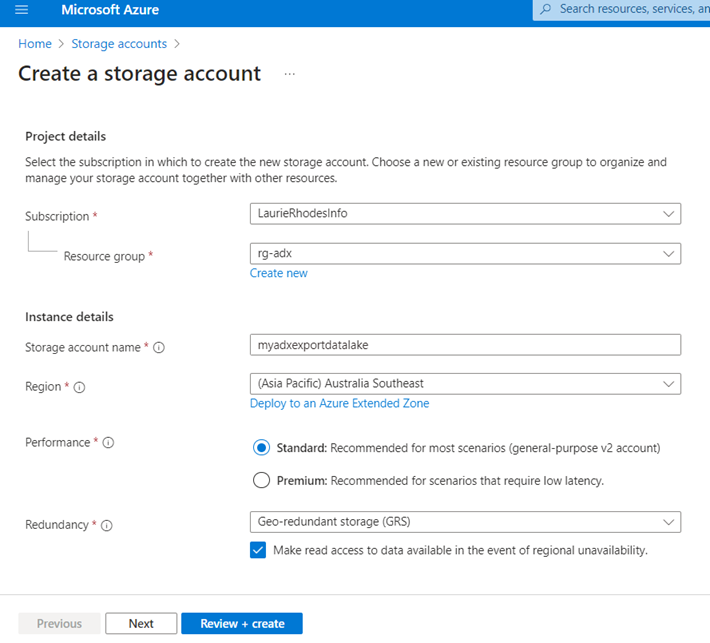
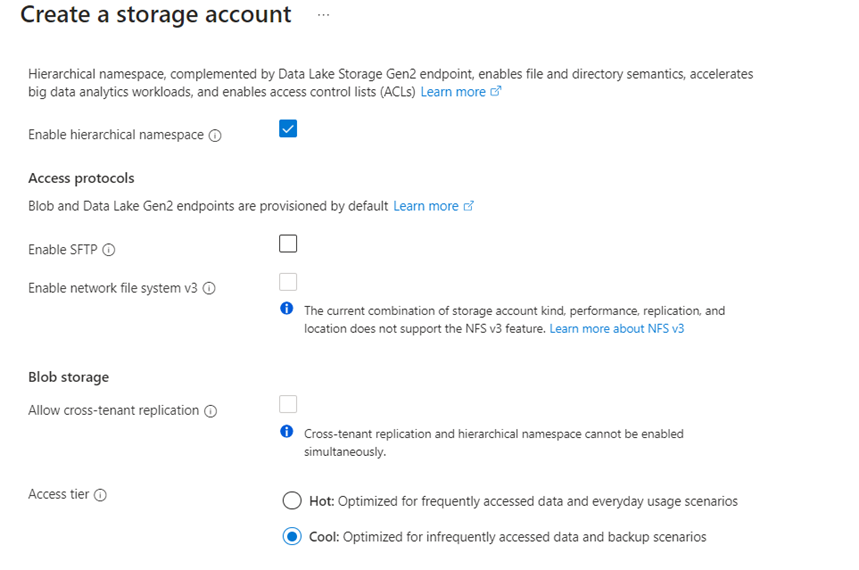
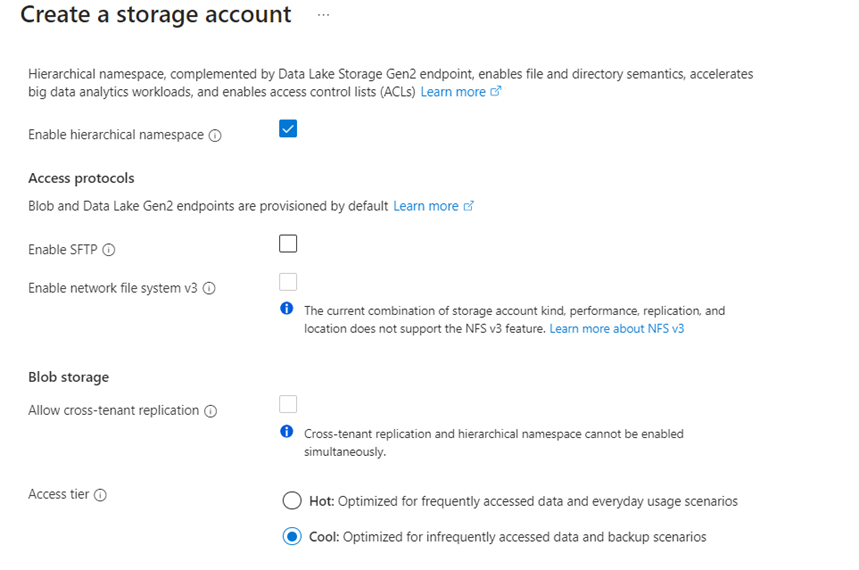
As our growth in event collection increases, the liklihood that enterprise organisations will eventually want to use Big Data processing against that data increases. I've decided to use Azure Data Lake Storage (hierarchical namespace) which will let me store blobs in directory structures that will be accessible by Big Data systems. I'm also going to use Geo-redundant storage to plan for the unlikley event that a complete Regional outage may impact security services.
I'll start by creating a Storage Account with Geo-redundant storage (GRS) enabled.
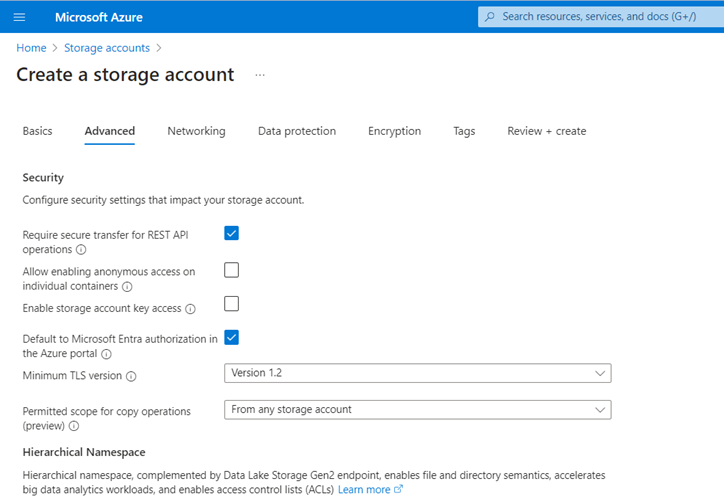
I really don't want keys to be used in accessing the Storage Account and I'll ensure that hierarchical namespace support is enabled.
I am not intending to use the exported blobs in day to day activity as that is the purpose of Azure Data Explorer, I'm going to set the default access tier to cool.
With my Storage Account deployed, I'll add my ADX cluster as a Storage Blob Data Contributor so it can write exported data to my designated container.
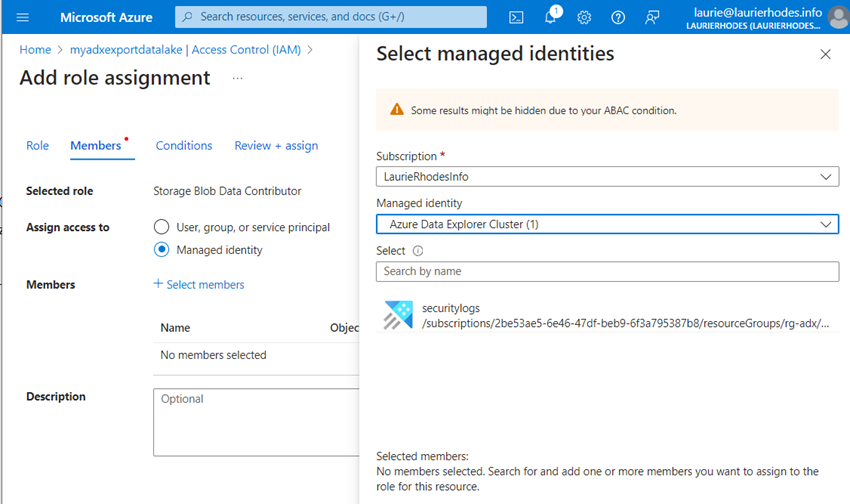
I need to also create a root container for the archived data that is to be exported.
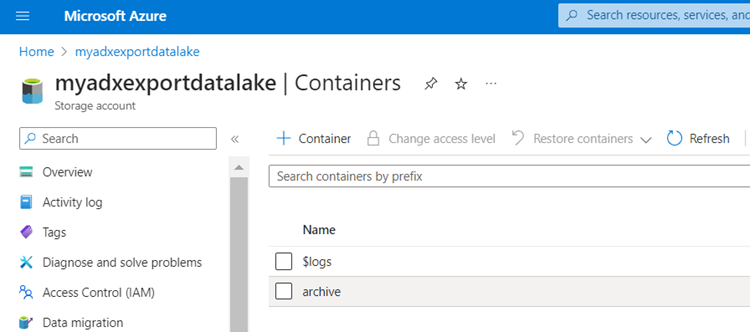
Now that I have a place to export data to, I will create export jobs against the different tables I have in Azure Data Explorer.
Azure Data Explorer Data Export
Previously, I've been through the exercise of creating the schema for each table within Azure Data Explorer.
Azure Data Explorer uses "external tables" for the continuous export process. In creating the external table, I need to run kql against my ADX database to define the schema for the data and then set details about the file format and data structure I want ADX to use in committing that data.
To .create-or-alter an external table using managed identity authentication requires AllDatabasesAdmin permissions.
Note that ADX uses ordered columns with data management so when the schema is defined, it must match the order of fields I use with the export process.
.create-or-alter external table ArchivedSyslog (
TimeGenerated: datetime,
EventTime: datetime,
Facility: string,
HostName: string,
ProcessID: int,
ProcessName: string,
SeverityLevel: string,
SourceSystem: string,
SyslogMessage: string,
TenantId: string,
MG: string,
HostIP: string,
Computer: string,
CollectorHostName: string,
_ResourceId: string,
Type: string)
kind=adl
partition by (HostName:string = HostName, Date:datetime = startofmonth (TimeGenerated))
pathformat=("Syslog/HostName=" HostName "/" datetime_pattern("yyyy/MM", Date))
dataformat=parquet
(
h@'abfss://archive@myadxexportdatalake.dfs.core.windows.net/;impersonate'
)
Some additional configuration settings to note with what I have set.
- 'kind=adl' specifies that the export is writing to Azure Data Lake.
- The data format I am using is Apache Parquet which, like ADX uses a columnar data storage approach with compression.
- h@'abfss://archive@myadxexportdatalake.dfs.core.windows.net/;impersonate' references the Data Lake storage I have just created. Impersonate is used for connecting with a Managed Identity rather than Storage Account keys. Also note how the container is referenced prior to the '@' symbol.
The path format and partitioning on my table are going to be completely subjective and unique with each table I export. I'm hoping that there is never a scenario where archived data needs to be retrieved but if there is a future situation where Security Operations need to retrieved archived logs for a particular system, I want to allow machine processing to be able to focus on querying data for that one machine without having recurse through millions of archived records. Almost all of the use-cases where Security Operations will want to run queries against my external table are going to involve a query based on the Hostname and event dates. Partitioning my data on these characteristics will be helpful should a future investigation.
I can also imagine that I might want to manage the lifecycle of data archived from various machines differently. To make that more managable, I might want to have different policies based on directory paths related to machines so structuring my 'syslog' data into folders using hostnames might be of future benefit.
ADX Permissions for data export
The Managed Identity account for ADX needs to be assigned permissions to be able to run the automated archive process against data within the ADX cluster. Using the object Id for my ADX Managed Identity, I will give the account read access to the ingested data:
.add database myDB viewers ('aadapp=5716bd1f-dd71-48c4-b376-XXXXXXXXXX')
I need to alter the database policy for Managed Identities to let the account authenticate to external storage and run the automated export job.
https://learn.microsoft.com/en-us/azure/data-explorer/kusto/management/managed-identity-policy
.alter database myDB policy managed_identity ```
[
{
"ObjectId": "5716bd1f-dd71-48c4-b376-XXXXXXXXX",
"AllowedUsages": "NativeIngestion, ExternalTable, AutomatedFlows"
}
]```
Creating the continuous export job
The continuous export runs "over" data ingested into my Syslog table in ADX with data being piped into my external table. Here I will specify the Managed Identity account being used and an acceptable interval for the job to be recursively run.
.create-or-alter continuous-export ExportSyslog over (Syslog)
to table ArchivedSyslog with
(managedIdentity='5716bd1f-dd71-48c4-b376-XXXXXXXXXX', intervalBetweenRuns=15m) <| SyslogWith the job created, I can start seeing blobs being written to storage in alignment to the structure previously defined.
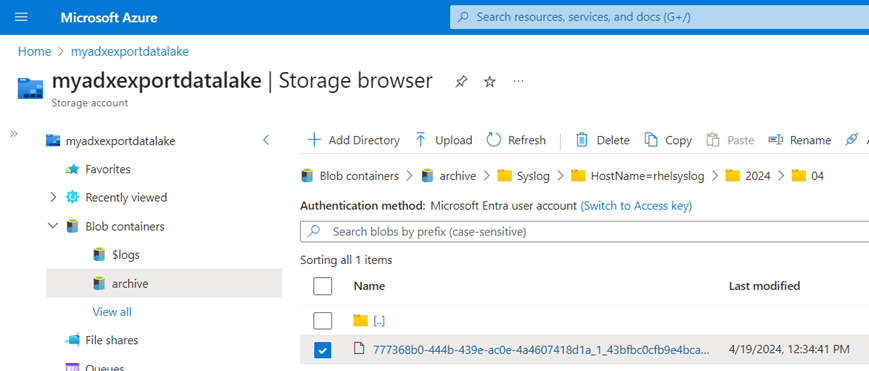
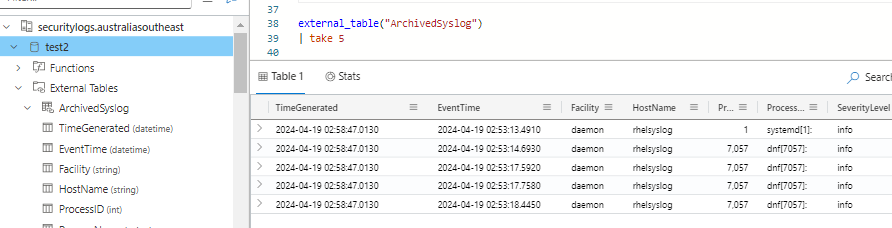
Azure Data Explorer is writing my structured security event data to my external table. This also means that I can use KQL to directly query that exported data from ADX as well.
Data Lifecycle Management
With my current use-case, Azure Data Explorer is scoped to be large enough to hold all the data I need for two years of querying. I'm unlikley to need to run queries directly against blob exported data but that may change as volumes of data collection increase.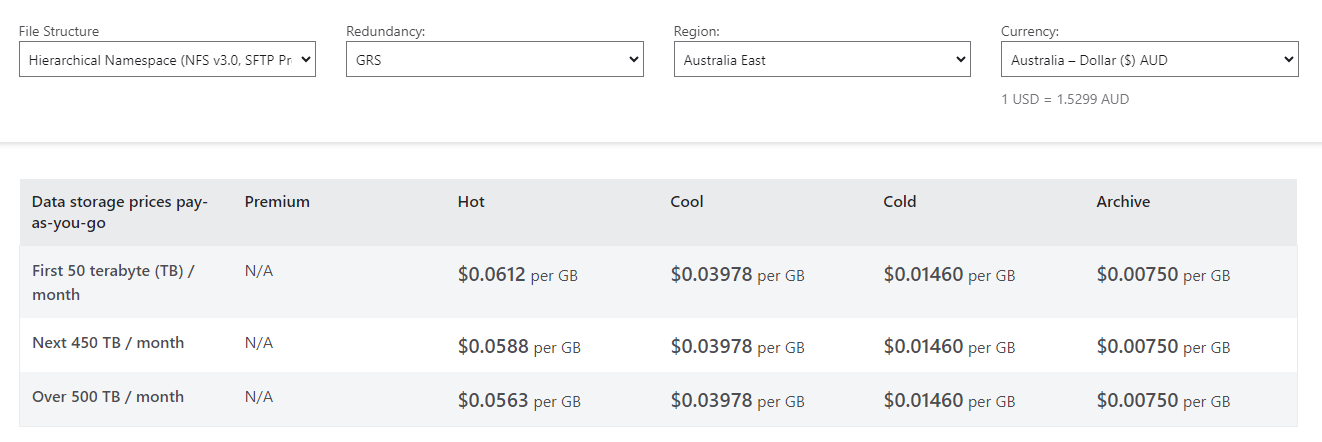
My intention is to focus on cost savings by using Cool tier storage for everything ingested and very quickly shift blobs to cold storage and much later on Archive tier storage.
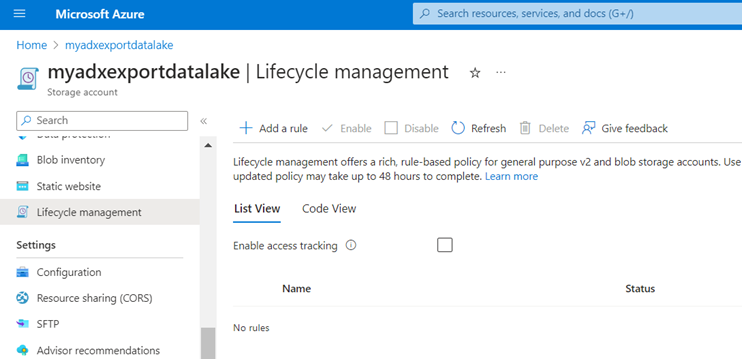
Storage accounts support lifecycle management with blobs and I can setup rules to shift data between storage tiers at different intervals.
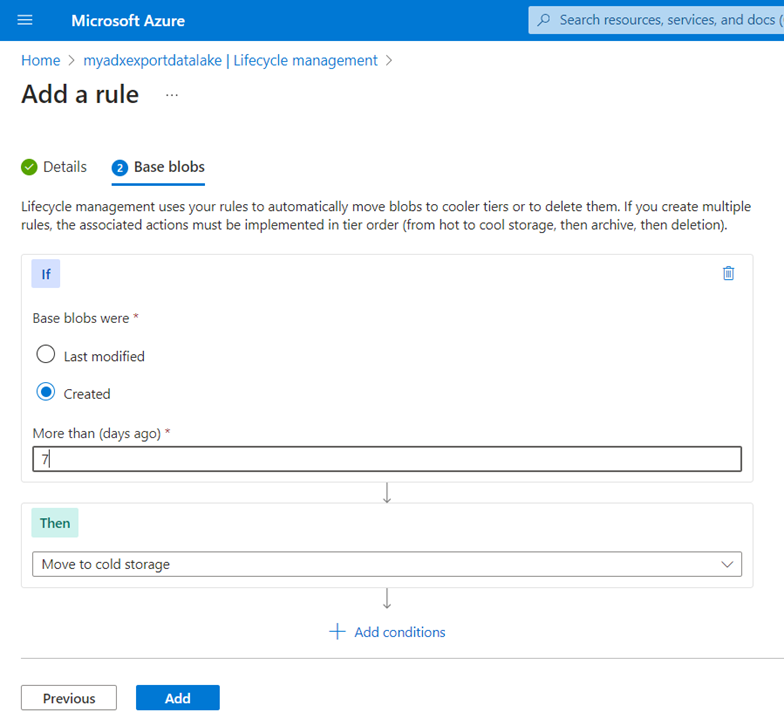
My use case with the continuous export capability with Azure Data Explorer is simply for Disaster Recovery planning as ADX is my large data archive. However, the long-term prospect of using a full Data Warehouse of structured security data being exported from ADX is an extremely interesting proposal that may have growing benefits beyond a simple archive capability.
- Log in to post comments